How Kubernetes halved our cloud spend, saved $3.9M/yr
We were burning about $6M/yr across AWS, Azure and GCP. We immediately cut this spend in half by repatriating workloads into a new Kubernetes-based private cloud, then saved even more as the private cloud grew.


Our business at Yellowbrick has been cash flow positive for the last few quarters. To get there, we had to cut cloud spend, in particular cloud consumption for software development across the three major cloud providers. Building an elastic, scale-out SQL data platform is really expensive: Compute is the most expensive cloud resource, and you're needing to exercise varying amounts of it across widely varying cluster configurations. We were burning about $6M/yr across AWS, Azure and GCP. We immediately cut this spend in half by repatriating workloads into a new Kubernetes-based private cloud, then saved even more as the private cloud grew. Kubernetes lets us do on-premises what could only be done in public clouds before.
Background
In late 2022, we were burning almost $6M/yr annualised across AWS, Azure and GCP. We develop with continuous integration - firing off PR-gate builds and tests with almost every check-in. Additionally, we execute hundreds of thousands of functional tests along with longevity testing, trying to stress the platform as much as possible and make sure that resource consumption and stability trend as expected. Our customers count on Yellowbrick to run workloads comprised of hundreds of terabytes or petabytes of data queried by thousands of vCPUs with high concurrency, across three public cloud providers. You might think that abstractions like Kubernetes mean we don't have to repeat this testing across clouds, but the reality is that K8s is much like POSIX – each vendor's implementation is a little different, likewise object storage and block storage and networking and everything else.
Yellowbrick traditionally sold appliances – custom servers designed and built by ODMs that were tuned to run our database. When we added support for cloud platforms in Yellowbrick 6, we extended the architecture to support full elasticity with separate storage and compute, persisting data on cloud object stores. We thought elasticity in the cloud had to be cheaper than building appliances, but we found out the hard way, it wasn't cheaper. It was much more expensive.
Our second-generation Andromeda appliance was a massive upgrade from our first-generation Tinman. When customers upgraded from Tinman to Andromeda, they traded in or returned their old Tinmen. We were sitting on hundreds of old Tinman servers, and didn't really know what to do with them. Over the 2022/2023 Christmas and New Year break, we decided to explore building a private cloud of Tinman servers, deploying K8s on it, and using it to run cloud workloads. It would be called Emerald City and known as EC3. The project was born.
EC3 architecture
To run Yellowbrick in a private cloud, we needed block storage, object storage, and of course plenty of networking and compute. Voluminous object storage was a necessity for large test data sets.
We created two classes of rack: Compute racks and object storage racks. Both would consist of Tinman servers. Object storage nodes run MinIO since it's an S3-compatible and K8s-friendly storage stack. For persistent block storage, we used LINSTOR running on compute nodes.

Networking and booting are complex. Tinman only supports 56 gigabit InfiniBand networking, and the blade servers boot over the network. So the core network in EC3 would be IB, not Ethernet, running IP-over-InfiniBand (IPoIB) to allow TCP and UDP traffic. We deployed other 1U servers running BGP Route Server for optimally routing packets between pods and transparently between the corporate networks and the EC3 IB network.
The Kubernetes control plane runs on three dedicated Tinman servers, along with a network booting service. kubeadm is used for deploying the control plane, wrapped in Ansible scripts. For CNI, we use a custom BGP-based implementation paired with kube-proxy in IPVS mode. IPVS mode is a special Linux kernel module that allows us to significantly reduce the number of firewall rules on each node and increase the throughput of Kubernetes services. We use ingress-nginx for exposing web-based applications to the corporate network. Standard open source packages like Prometheus and Loki are deployed for observability.
After getting everything working, we wiped it all down and re-installed it, just to make sure the Ansible playbooks were correct and complete. We started running some production workloads on EC3 in mid-2023, and by the start of 2024 had repatriated many services from public clouds.
Savings and more savings!
The chart below shows spend per month, measured in millions.
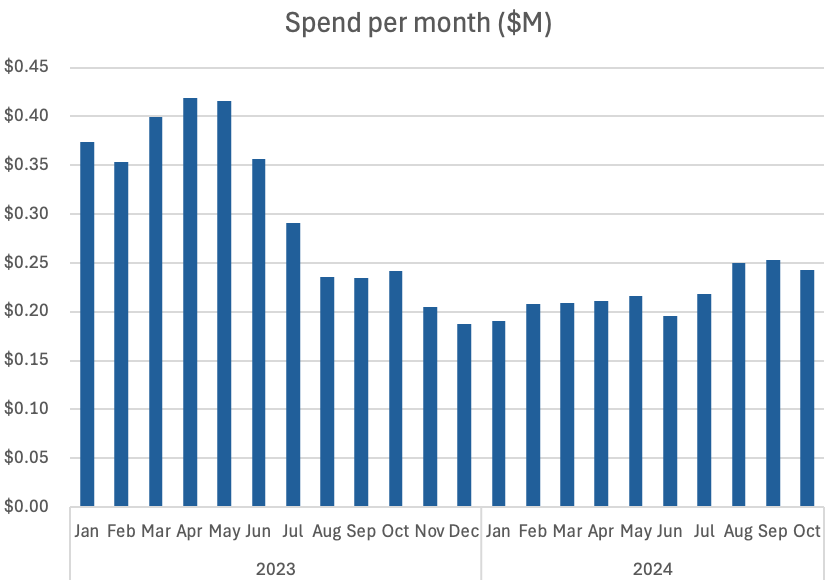
In April to May 2023, we were spending over $400,000/month, but by the end of 2023 we had reduced this to $200,000/month, saving around $2.4M a year, however there are other peripheral costs we need to consider.
Peripheral costs
Developing, testing and deploying this stack, along with the data centre work, cost the equivalent of two full-time engineers for about six months. Interestingly, ongoing administration cost is really no higher than AWS. One staff member in Utah, near the data centre, spends a fraction of his time doing break/fix and taking care of the physical aspects. For most of EC3's lifetime system administration has been done by 2-3 developers for a handful of hours a week.
We have to pay for the co-lo facility in Utah which provides the data centre, power and network connectivity for EC3. Utah is a particularly low-cost region; we spend only $50,000 per month all-in.
Today the footprint of EC3 has grown far beyond the initial deployment, and the workloads have grown in complexity far beyond what we were running on public clouds. For example, we're now running richer and more frequent CI gates than we'd be able to comfortably afford in AWS, Azure and GCP, as well as other new applications we have developed, increasing the quality of our software with negligible increase in cloud costs.
Today, EC3 has over 200 Tinman servers in the private cloud, totalling 8064 vCPUs, along with around 2 petabytes of object storage. Because our hardware was returned from customers, the only real cost of keeping going is the $50,000/month co-lo fees, totalling $600,000/year.
Estimated public cloud cost
Using AWS as an example (our workloads run across all three clouds), in AWS, each vCPU, one year reserved on a smaller sized x64 instance costs about $487.82 each, so 8064 vCPUs of compute would cost around $4M/yr. Object storage would be another $0.5m per year, so a total spend of about $4.5M/yr. We're saving $3.9M a year.
Just to reiterate that. $3.9M per year. This is an enormous saving, but we're not alone in experiencing this. Read about a similar story from the makers of Basecamp here.
What this might cost someone else
Although these are Yellowbrick costs, we are in an advantageous position because we are re-deploying old servers that have already been paid for and subsequently returned to us: The servers, switches and storage are essentially free by the time they make it to EC3. If another company had to buy rack-mount servers and switches from SuperMicro, for example, the initial capital outlay would be approximately $1.3M of compute, $80,000 of switching and cables, and $270,000 of SSD storage for the object store, so in year 1, an extra $1.65M of capital expenditure.
The savings are still substantial in year 1, and even greater in year two and year three since the capital costs are not recurring. Smaller businesses could spread the capital expenditure over several years through a variety of financial mechanisms to make the upfront cost even more palatable. The only requirement is to make sure software isn't too hardwired to a given cloud provider's platform.
Future enhancements
Our usage of cloud grew organically and we can't quite attribute costs to projects and organisations as easily as we wish. We plan to further reduce cloud spend by forcing more detailed tagging, by organisation, owner and cost accounting unit, of every single cloud resource across all cloud providers, along with deploying an automatic assassin for unaccountable resources.
As EC3 grows, hardware failures are becoming more commonplace, occurring perhaps once every couple of weeks. We normally observe hardware failures through issues in the software stack and manually cordon off nodes. We plan to deploy the Node Problem Detector (NPD) with added custom probes for common classes of Tinman hardware failure to automate this process.
Finally, we are starting to integrate newer and more advanced server platforms from DELL, SuperMicro and others into EC3 for developing and testing our third-generation appliance architecture. The third-generation Yellowbrick appliances, codenamed Griffin, will be powered by RedHat OpenShift. They take many of our learnings from building EC3 and productise the fully elastic SQL data platform for our on-premises customers.
This isn't a popular message
For start-ups where workloads are costly and compute-bound (not simple SaaS business applications) the ideas that I've shared here:
- You shouldn't be coupling your software to custom cloud vendor APIs
- You should be building portable software using Kubernetes
- You should be running workloads in a co-lo "on-premises" data centre
- Using the cloud only when needed for short term capacity and convenience
...are still largely unpopular. When I've heard others trying to share these viewpoints, they have been accused of lying, not calling out hidden costs, being backward, etc. My article here is certainly not a detailed financial breakdown, and no doubt smaller items have been glossed over, but everyone from our CFO to our operations department to our board members have seen how the savings have been one of the key factors that have enabled our business to make money, instead of lose money. We simply consume so much compute that by owning it, rather than subscribing to it in a cloud platform, the savings are obvious.
Kubernetes is the game changer because all the elasticity, scale up/down, and flexibility that used to require the public cloud can now be done on equipment we own, too.
We aren't alone. Just recently I was approached by board members on behalf of two of their SaaS portfolio companies who were being asked by their enterprise customers to make their applications run on-premises as well, for cost-savings and security reasons.